
Where is the wisdom we have lost in knowledge?
Where is the knowledge we have lost in information?
T.S. Eliot
Généalogie et Web des données
- Les personnes dans le Web des données
- Monde clos et monde ouvert
- Données personnelles et "communs généalogiques"
- Travaux pratiques 1 : Requêter et enrichir Wikidata
- Travaux pratiques 2 : Publ-lier sa généalogie dans le Web des données
Les personnes dans le Web des données
Le Web des données, en anglais Linked Data a maintenant plus de dix ans d'existence et continue de croître, lentement mais sûrement. Moins visible et moins tapageur que le Web marchand et celui des réseaux sociaux, ce Web de la connaissance est le fruit d'un long et patient travail réunissant les instances de normalisation du Web sous l'égide du W3C, les grandes bibliothèques, les fournisseurs de données de référence comme l'INSEE ou l'IGN, les instituts de recherche, auxquels se joignent une multitude d'autres initiatives publiques ou privées, toutes partageant une seule et même vision, construire un espace décentralisé mais unifié de connaissances interconnectées, partageant des standards ouverts et non propriétaires. On y trouve par exemple les listes d'autorités et catalogues des grandes bibliothèques, des référentiels géographiques publics ou privés, etc.
Le Web des données s'appuie sur une pile de standards: un format de données universel (RDF), un langage de requête (SPARQL), les protocoles et identifiants du Web (HTTP, URI), et sur une démarche de collaboration ouverte. Il n'est donc pas étonnant de trouver au cœur du Web des données la fondation Wikimedia avec son initiative Wikidata, qui mutualise la description des entités décrites dans ses différents projets comme Wikipédia, Wikispecies, Wikibooks, en y attachant les identifiants utilisés par les grands index publics.
Les personnes, vivantes ou décédées, réelles ou imaginaires (héros de fiction, personnages mythologiques) sont les entités les plus omniprésentes du Web des données. La base Wikidata en compte à ce jour plus de quatre millions. Le nombre d'individus répertoriés dans les bases de données généalogiques dépasse le précédent de plusieurs ordres de grandeur, puisqu'il atteint ou dépasse plusieurs milliards pour les plus importantes d'entre elles comme Geneanet ou MyHeritage. Mais ces bases utilisent des formats propriétaires, des modèles de données non extensibles, et ne reliant pas de façon standard les personnes à d'autres entités comme les lieux, les événements ou les œuvres. On ne peut pas considérer leur contenu comme faisant partie du Web des données, même s'il est accessible via le Web. Elles ne remplissent aucune des conditions pour être des données "cinq étoiles".
Le Web des données ne contient de fait que des personnes qui ont une certaine notoriété. Cette notion assez floue est encadrée par des règles assez strictes pour l'admission dans Wikidata. Ces personnes "notables" sont souvent répertoriées dans des dizaines d'index, catalogues, listes d'autorités... Un effort considérable a été réalisé à l'initiative notamment des grandes bibliothèques pour aligner les représentations et les identifiants, regrouper les variantes des noms autour d'un identifiant commun, via des initiatives comme VIAF ou ISNI.
Mais, si on excepte des exemples très particuliers comme les dynasties royales, la notoriété n'est pas héréditaire. Il en résulte que l'information généalogique sur le Web des données est très fragmentaire, elle n'est vraiment bien renseignée sur plusieurs générations que pour les dynasties, typiquement les familles royales d'Europe. Donc si le roi n'est pas mon cousin, ma généalogie n'y figure pas.
Par ailleurs, comme le montre le tableau suivant, la dite notoriété est loin de respecter la parité homme-femme! En particulier, nombre de filles, de mères, d'épouses ... de personnes plus ou moins célèbres, citées dans des articles de Wikipédia, sans avoir été considérées elles-mêmes comme suffisament notables pour faire l'objet d'un article à part entière, sont absentes de Wikidata. Elles sont pourtant souvent des chaînons manquants dans le graphe généalogique, et peuvent y être ajoutées selon une interprétation souple des critères de notoriété cités plus haut, notamment le point 3.
[Un élément est acceptable] ... s'il remplit un besoin structurel, par exemple lorsqu’'il est nécessaire pour rendre plus utiles des déclarations faites dans d'autres éléments.Le tableau suivant rassemble quelques statistiques obtenues par des requêtes de comptage sur Wikidata. Les chiffres sont indicatifs (arrondis au millier le plus proche) et seront mis à jour régulièrement, on peut obtenir les valeurs en temps réel en cliquant sur le nom de la requête dans la colonne de gauche.
NB - Décembre 2019 : Les chiffres du tableau ci-dessous actualisés le 7 décembre 2019, montrent une très forte progression du nombre de relations généalogiques, dûe à l'import dans WikiData de la base de données The Peerage, contenant plus de 600000 personnes, toutes plus ou moins liées à l'aristocratie européenne. Cet import a un peu corrigé la parité homme-femme ... mais certainement pas la parité sociologique!
| Intitulé de la requête | 01/08/2019 | 07/12/2019 |
|---|---|---|
| Nombre de pères (objets d'une relation "a pour père" wdt:P22) | 147000 | 406000 |
| Nombre de mères (objets d'une relation "a pour mère" wdt:P25) | 42000 | 195000 |
| Nombre d'individus reliés à leur père (sujets d'une relation "a pour père") | 220000 | 765000 |
| Nombre d'individus reliés à leur mère (sujets d'une relation "a pour mère") | 62000 | 482000 |
| Nombre d'individus reliés à leurs deux parents (sujets d'une relation "a pour père" ET d"une relation "a pour mère") | 54000 | 472000 |
Monde clos et monde ouvert
Faire sortir des données (généalogiques ou autres) des "silos" que représentent les bases de données, logiciels et formats propriétaires, pour les pub-lier sur l'espace ouvert du Web, c'est-à-dire les lier publiquement à d'autres données publiques, est un changement de paradigme qui impacte aussi bien les architectures techniques et les modèles de données que les modes de travail, voire les modes de pensée.
On définit souvent la différence entre monde clos (celui des bases de données propriétaires) et monde ouvert (celui du Web des données) par la formule suivante
Dans un monde clos, tout ce qui n'est pas explicitement autorisé est impossible.
Dans un monde ouvert, tout ce qui n'est pas explicitement interdit est possible.
Illustrons par un exemple simple. L'interface du logiciel de généalogie que j'ai sur mon bureau me donne pour chaque individu la possibilité de spécifier un père et un seul, de genre masculin, et une mère et une seule, de genre féminin. Toute situation en dehors de ce schéma est impossible à saisir dans l'interface, et donc à stocker dans les formats de données : famille homoparentale, gestation pour autrui, changement de sexe d'un des parents, sans préjuger de ce que nous réserve l'avenir, même si nous ne souhaitons pas le voir survenir. Autre exemple, parmi les événements de la vie spécifiés dans le menu par défaut, on trouve "baptême" et "inhumation". Mais ce qui intéresse l'utilisateur chez ses ancêtres, ce sont peut-être plutôt leurs œuvres, leurs réalisations, s'ils ont participé à la construction d'un pont, d'un château ou d'une cathédrale, ou exploré les premiers des territoires inconnus, ou inventé la machine à coudre. Et tout cela il ne pourra l'indiquer que dans un champ texte libre sous une rubrique "autre".
Sans aller plus loin, on voit bien que des choix de représentation sont "câblés en dur", comme disent les informaticiens, dans le modèle de données et dans l'interface du logiciel qui permet de les saisir et de les modifier. Un logiciel et le format de données qu'il supporte sont en effet, dans un monde clos, toujours un compromis entre une représentation du monde ou d'un "domaine métier", autrement dit une culture d'entreprise ou de communauté, (dans le cas qui nous occupe une culture tout court, voire une religion) et les exigences d'un système technique. Bien souvent, des considérations de performance et de scalabilité font rejeter certaines options de modélisation qui répondaient pourtant plus précisément au cahier des charges de l'utilisateur. Celui qui modélise les données doit souvent revoir sa copie après une remarque du genre C'est très beau ton truc, mais ça multiplie les temps de requête par dix!
Dans la logique de monde ouvert du Web des données, au contraire, rien n'est impossible. Toutes les situations, y compris celles que nous ne pouvons pas imaginer aujourd'hui, seront représentables sans avoir à changer de modèle ou de format de données, et sans avoir à changer de logiciel. Il suffira d'ajouter de nouveaux prédicats, de nouvelles classes, de modifier quelques règles d'inférence si on fait du raisonnement. Les nouvelles données viendront s'ajouter à l'existant sans nécessiter une migration lourde et coûteuse. Les données liées croissent de façon organique et décentralisée, et bien sûr pas nécessairement cohérente. Exprimées dans un format standard, ouvert et extensible, elles peuvent être triées, filtrées, être intégrées dans un système clos et plus contraint, pour en inférer de la connaissance ou tester leur cohérence via des règles logiques.
En conclusion, les données liées publiques telles que celles de Wikidata constituent des communs de la connaissance, que chacun peut contribuer à enrichir, et où chacun pourra puiser pour les relier à ses données privés, qui pourront être gérées dans une base de données locale en utilisant le même format générique (RDF).
Tout cela ne va pas bien sûr sans poser quelques questions techniques intéressantes. Les logiciels dédiés utilisent des algorithmes de parcours et d'extraction de graphes optimisés pour les données généalogiques. Extraction à la demande de l'arbre des ascendants ou des descendants, chemins d'un individu à un autre, le moteur GeneWeb qui outille des sites comme Geneanet ou la base Roglo est à cet égard très performant et robuste. Roglo répertorie plus de sept millions d'individus, tous connectés par des liens de filiation ou d'alliance. Ces algorithmes pourraient-ils être déployés avec une même efficacité sur une base de données RDF, riche et donc encombrée de données non spécifiquement généalogiques?
Données personnelles et "communs généalogiques"
Au-delà des problèmes techniques, la protection des données personnelles dans les bases généalogiques est une question délicate. La déontologie usuelle sur des sites comme Geneanet ou Roglo est d'anonymiser dans les interfaces Web publiques les personnes "contemporaines", nées il y a moins de 100 ans pour Geneanet, moins de 120 ans pour Roglo. Cette règle souffre cependant de nombreuses exceptions. Certains arbres Geneanet affichent tous les contemporains en clair, car l'option par défaut de masquage peut être levée à tout moment par le propriétaire de l'arbre. De plus, les personnes "notables" apparaissent la plupart du temps en clair, ce qui pose le problème déjà évoqué de la définition assez floue de la notoriété. Par ailleurs le mode "ami" ou "invité" sur un arbre permet d'avoir accès aux informations masquées au grand public. Ainsi, une personne vivante présente dans l'une de ces bases mais qui n'y aurait accès qu'en mode public ignorera quelles informations sont cachées derrière le xx pudique qui est censé assurer son anonymat, et ignore encore plus qui a accès à ces informations en clair. Le nombre d'éditeurs (ayant accès à toute la base en lecture et écriture) dépasse la centaine pour certains arbres Geneanet collaboratifs comme Pierfit, et Roglo compte plus de 250 magiciens. Quant aux amis ou invités ayant accès en lecture à toutes les données, même masquées, leur nombre est inconnu, mais il se chiffre sans doute en milliers. Sachant que ces bases contiennent plusieurs millions de personnes dont une grande partie est contemporaine ou vivante, cela fait beaucoup de monde ayant accès à beaucoup de données supposées "non publiques". Comme la notoriété, la notion de publicité a des limites très élastiques. La nouvelle réglementation européenne (RGPD), en application depuis mai 2018, demande que le consentement explicite des personnes vivantes soit obtenu avant leur intégration dans une base de données. Sa mise en œuvre pratique pour les bases de données en question semble plutôt problématique, étant donné le nombre de personnes concernées.
Si les données généalogiques concernant les vivants et leurs proches constituent sans doute possible des données personnelles, à partir d'où dans le passé peut-on considérer que ces données ne sont plus personnelles mais historiques, et font à ce titre partie des communs de la connaissance? Les limites adoptées par Wikitree semblent raisonnables. Le profil de toute personne née il y a plus de 150 ans et/ou décédée il y a plus de 100 ans est obligatoirement public, et ouvert à l'édition de tous les collaborateurs. Pour les profils plus récents, plusieurs niveaux de confidentialité sont possibles, autorisant l'accès en lecture et/ou écriture à une "liste de confiance".
On soutiendra ici que les données liées ouvertes, utilisant des formats non-propriétaires et libres de droits, constituent actuellement la meilleure option de représentation et de partage de ces communs généalogiques, et que les données déjà présentes dans Wikidata constituent un noyau qui peut être considérablement enrichi, même si la question de l'intégration des données généalogiques des personnes "non notables" est toujours un sujet ouvert. Plusieurs projets dans ce sens ont été proposés, soit dans le cadre de Wikidata, soit dans des extensions spécifiques. Aucun consensus clair ne s'est dégagé dans la communauté, ce qui n'empêche pas les données généalogiques de continuer à s'ajouter à la base de connaissance, lentement mais sûrement. Ce qui est peut-être aussi bien.
Travaux pratiques 1 : Requêter et enrichir Wikidata
Exemple 1 : Les descendants d'Anne de Bretagne nés en France au XIXème siècle
Pour illustrer les possibilités du Web des données en terme de recherche généalogique, on utilisera le service de requête SPARQL sur la base Wikidata.
L'image ci-dessous est une capture d'écran d'une requête exécutée via ce service, requête qui peut s'intituler :
"Les descendants d'Anne de Bretagne nés en France au XIXème siècle, classés par date de naissance croissante, avec leur nom en français et en option celui de leurs père et mère".
La partie gauche de l'écran est une interface d'aide à la construction de la requête, qui apparait dans la fenêtre de droite dans la syntaxe standard SPARQL.
Anne de Bretagne est l'entité wd:Q201143. Les descendants recherchés sont reliés à cette entité par une chaîne d'un nombre quelconque de propriétés "a pour père" (wdt:P22) et/ou "a pour mère" (wdt:P25). La date de naissance est indiquée par la propriété wdt:P569, le lieu de naissance par la propriété wdt:P19. Le lieu de naissance est lié par la propriété wdt:P17 au pays wd:Q142 qui est la France.
Les différents filtres de la fin de la requête imposent la langue des noms (Wikidata est multilingue, comme Wikipedia), et la plage de dates, dans le format de dates standard AAAA-MM-JJ.
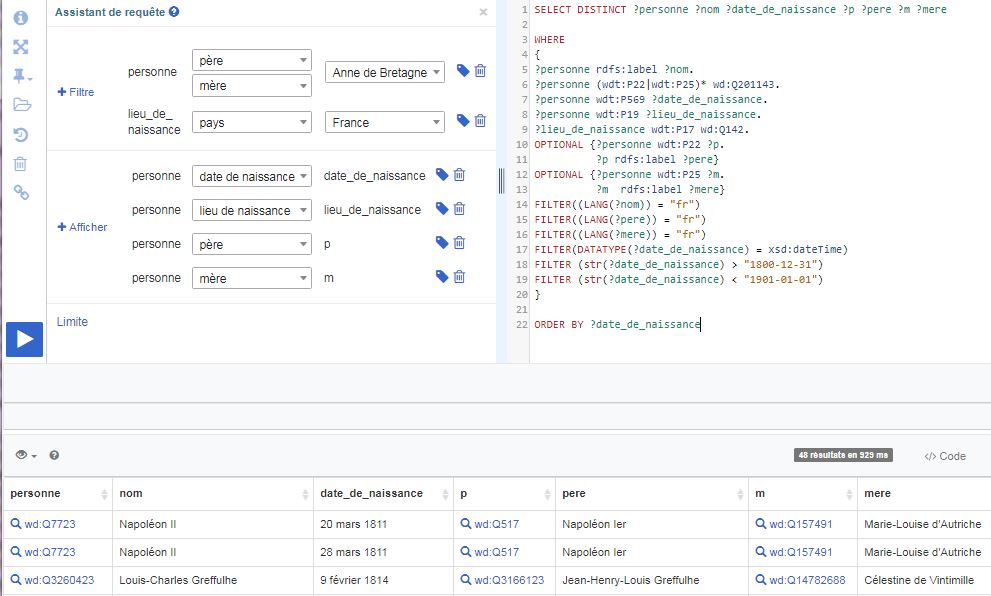
La capture d'écran ci-dessus montre les premières lignes des 48 résultats obtenus à la date où la requête a été exécutée (2018-08-11). Cette requête peut être rejouée à tout moment via un lien pérenne qu'on peut stocker dans ses favoris.
Cet exemple illustre déjà quelques avantages de ce type de représentation par rapport aux bases de données "purement" généalogiques. Wikidata relie les personnes entre elles par les relations de filiation et d'alliance, comme une base de données généalogiques, mais elle relie aussi les personnes à d'autres entités, dans ce cas les lieux de naissance et les pays, mais qui pourraient être aussi bien des événements, des organisations ou des œuvres d'art.
On notera que les deux premières lignes donnent deux dates de naissance différentes pour Napoléon II, alias l'Aiglon. La consultation de la fiche Wikidata permet de tracer la source de la valeur discordante, à savoir les données liées d'une notice d'autorité de la très respectable Deutsche National Bibliothek (la date de naissance est tout en bas de la page).
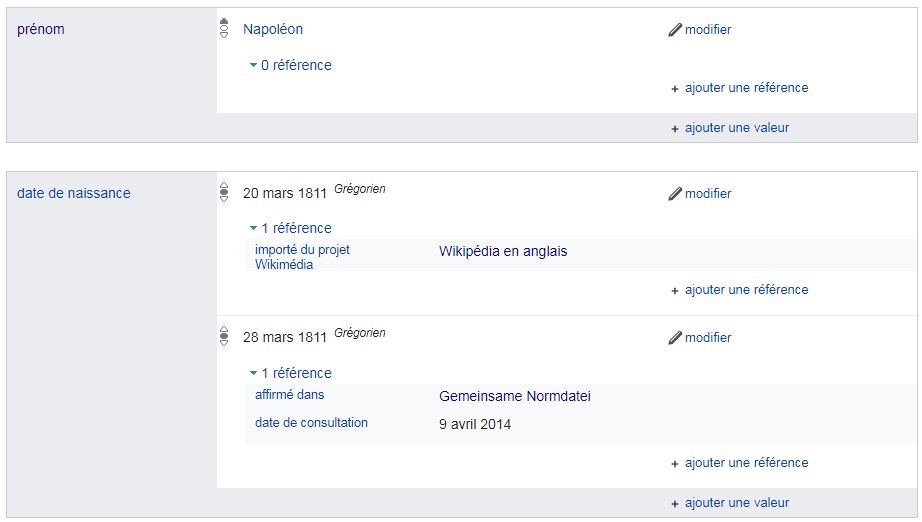
Cet exemple montre aussi comment faire cohabiter des données non cohérentes en citant leurs sources, un aspect particulièrement intéressant en généalogie, où les versions différentes des faits sont fréquentes.
Exemple 2 : Adélaïde de Béziers et sa descendance cognatique
Partant toujours d'Anne de Bretagne, recherchons dans Wikidata toutes les femmes qui lui sont reliées par une succession de relations mère-fille, autrement dit toutes les ascendantes, et toutes les descendantes de ces dernières, par lignée cognatique uniquement. En option on demandera les dates de naissance et de décès quand ces éléments sont renseignés. Les résultats seront classés par date de naissance croissante. La requête est accessible via ce lien. A la date du 1er août 2018 elle ramène 303 résultats s'étalant du 12ème siècle au début du 21ème, les plus longues chaînes comportant plus de trente générations, toutes issues d'une ancêtre commune Adélaïde de Béziers.
La descendance de cette dernière comprend plus d'un million d'individus répertoriés selon la base Roglo, dont une infime minorité (moins de 1%) possèdent une notoriété suffisante pour être présents dans Wikidata. Cette requête permet de les compter. Et à vrai dire, Adélaïde elle-même n'était pas présente dans Wikidata avant que je ne l'y ajoute, car elle ne faisait pas (encore) l'objet d'un article Wikipédia. Par contre elle était citée dans les articles concernant son père Raimond Ier Trencavel, son époux Guillaume II de Forcalquier et sa fille Garsende de Forcalquier. Ce qui peut passer, comme dit plus haut, pour des critères suffisants pour l'ajouter à Wikidata.
Exemple 3 : Ascendance cognatique de Prosper Mérimée, et autres "chaînons manquants"
Dans la même logique que l'exemple précédent, il manquait dans Wikidata les deux femmes reliant Prosper Mérimée à son arrière-grand-mère maternelle Jeanne-Marie Leprince de Beaumont. Ce lien est maintenant assuré par l'ajout des éléments Anne Louise Moreau et Elisabeth Charlotte Leprince de Beaumont . La relation entre Prosper Mérimée et son arrière-grand-mère a été déduite d'une lecture des articles Wikipédia le concernant, et les éléments de description de sa mère et de sa grand-mère extraits de bases de données généalogiques externes à Wikidata.
Il existe de multiples exemples du même type dans Wikidata. Par exemple ce rapport automatique signale les relations entre un individu et un grand-parent où le parent intermédiaire n'est pas identifié. Il est souvent possible de retrouver le chaînon manquant et de l'ajouter à Wikidata, voir mes contributions récentes à ce chantier.
Exemple 4 : Relations mère-enfant incomplètes, litigieuses ou incohérentes
Fruits d'un travail collaboratif, issues de sources multiples, les données Wikidata sont par nature incomplètes, sujettes à erreur, et nécessitent un travail permanent de curation. Des contrôles automatiques sont effectués périodiquement pour détecter les éléments dont la description utilise des propriétés de façon non conforme aux contraintes du modèle. Par exemple cette page reporte les anomalies dans l'usage de la propriété "a pour mère". Ce type de rapport permet aux éditeurs de corriger les anomalies ou de valider les exceptions, et si besoin de faire évoluer les contraintes du modèle en tenant compte de l'usage réel dans les données. Par exemple la contrainte d'unicité de la propriété "a pour mère" est discutable, par exemple dans le cas des individus ayant une mère biologique et une (ou plus) mère adoptive.
Contrairement à un modèle de données de monde clos, le modèle ouvert de Wikidata accepte les entorses au modèle tout en les signalant. Une anomalie n'est pas bloquante, elle peut être conservée comme exception au modèle recommandé, et si elle se répète, provoquer une évolution du modèle.
Travaux pratiques 2 : Pub-lier sa généalogie dans le Web des données
Si mes ascendants ne sont pas notables au sens de Wikidata, comment les relier au Web des données? Je peux utiliser dans une base de données locales (une base de données RDF, ou un simple fichier) le même vocabulaire que Wikidata pour représenter les relations entre mes ancêtres, leurs collatéraux et leurs descendants. Si par hasard je rencontre en chemin une personne identifiée dans Wikidata, j'utiliserai son URI Wikidata dans mon fichier local, et je pourrai récupérer depuis cette URI les éléments de description qui m'intéressent.
La copie d'écran ci-dessous est extraite de l'excellent arbre Geneanet de Yves Hamet, qui a bien voulu y accueillir une partie de mes ancêtres. Yves-Marie Corre est mon grand-père maternel, Victor Segalen figure dans Wikidata sous le matricule Q462604.

Un cousin au 5ème degré de mon grand-père maternel
Nous allons voir maintenant comment publier l'information correspondant à ce graphe généalogique dans le format du Web des données.
Ce fichier RDF Turtle contient pour le moment la description de mes ancêtres sur six générations, au complet depuis mes grands-parents jusqu'à la génération d'Anne Salaun, la génération précédente est incomplète. Tous les individus de l'arbre ci-dessus sont présents, plus quelques descendants notables de Victor Segalen présents dans Wikidata et sur lesquels nous reviendrons. La racine de l'arbre est décrite a minima (juste un nom) et identifiée au créateur du fichier dans les métadonnées. Quant à ses parents, nés il y a moins d'un siècle, ils sont identifiés par une simple URI sans autre propriété que de faire le lien entre le petit-fils et ses grands-parents. Il n'y a donc pas ici de données "masquées" sur ces parents, en-dehors de leur existence dans l'arbre.
Les éléments de description de chaque individu utilisent, dans la mesure où leurs valeurs sont connues, les propriétés suivantes définies dans le vocabulaire Wikidata. Toutes les personnes sont de plus déclarées de type Person dans le vocabulaire schema.org.
- wdt:P21 (sexe ou genre, valeurs wd:Q6581097 pour masculin, wd:Q6581072 pour féminin)
- wdt:P735 (prénom)
- wdt:P734 (nom de famille)
- wdt:P569 (date de naissance au format AAAA-MM-JJ)
- wdt:P570 (date de décès au format AAAA-MM-JJ)
- wdt:P19 (commune de naissance, identifiant Wikidata)
- wdt:P20 (commune de décès, identifiant Wikidata)
- wdt:P22 (identifiant du père)
- wdt:P25 (identifiant de la mère)
- wdt:P31 (valeur wd:Q5 pour indiquer qu'il s'agit d'un être humain)
- wdt:P2949 (identifiant WikiTree)